Sip Servlets 1.1 enjoys great adoption in the telco industry displacing proprietary and legacy applications. One of the big promises of Sip Servlets 1.1 is the application (WAR module) composition and isolation provided by the Application Routing feature which is supposed to allow the applications to grow over time independently from each other and orchestrated in different services.
On the surface...
Application Routing is probably one of the most misunderstood parts of the specification. Misunderstood not in terms of function, but in terms of use and consequences. From JSR-289 application routing is described as a separation of concern concept similar to the
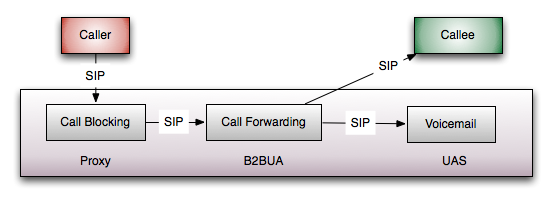
Chain of Responsibility Design Pattern where each application is responsible for it's own small part of the service and can be added or removed on demand. In fact it would often look like a pipeline on your architecture diagrams:
- Call Blocking will check if the Callee has blocked the Caller and if so it will reject the call. Otherwise if the the Caller is not blocked it will just proxy the call to the next app.
- Call Forwarding will forward the call to the Callee or her voicemail depending on availability status.
- The Voicemail application (if reached) will act on behalf of the Callee and it will answer the call to record a message.
Looking great - clear responsibilities for each application, zero coupling, applications are completely unaware of each other, ..blah, blah, blah. Every architect's dream!
The Real World Picture
What is not shown in these diagrams however is how it works inside the container with all external entities. JSR-289 mandates that applications communicate with each other through SIP, which means all messages go up and down the stack to reach the next application. Internally, Mobicents and most Sip Servlets containers optimize the message passing by skipping a few stages of the SIP protocol stack, but still you have to do it. And that's not the problem at all. There are a number of things from the real world that are missing in the picture:
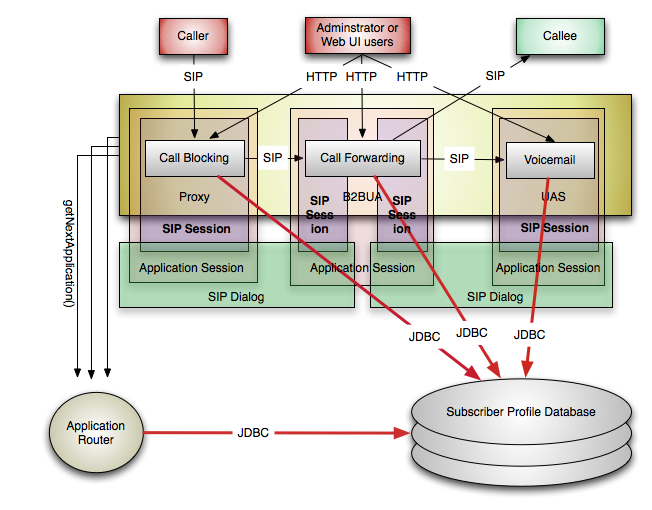
Each application creates it's own application session. The B2BUA application creates two Sip Sessions while the Proxy and the UAS application create one session each. Additionally if the container operates with dialogs it will create 2, 3 or 4 dialog representations. Sip Servlets applications have no awareness of the SIP dialogs and have no references to dialogs directly but they are in the memory. The Sip Servlets specification says that dialogs roughly correspond to SipSessions, which is true from application point of view, but in SIP terms the dialog spans from UAC to UAS through any proxies in the way, thus in the best case it is possible two or more sessions to share the same dialog instance if they are on the same machine.
So what's the big deal? The applications care only about their own state and not the other application's state, right? Not exactly. To maintain the call internally, the containers keep references to a number of objects that represent the transactions or the the application routing chain in some way. SipApplicationSessions have timers associated with them and so do the SIP client and server transactions. B2BUA and proxy implicitly have to keep the associated inbound and outbound requests/responses. There are also a number of properties that users can specify and are maintained in memory. That's just for empty sessions. Once the developers start adding session attributes independently for each app, it is almost certain that they will have duplicate data.
In real-world applications most of the data would be somewhere in persistent storage such as a database. The data would be queried and loaded in the sessions by the applications. Because the applications can't share state they will have to query the database independently and very likely transfer and use duplicate data like the user profiles and preferences. Note that I am not assuming that it has to be that way. You may be able to organize the data and the queries not to transfer redundant data, but this is very hard to do correctly over time and especially when you need to have separate Web UI to access the data. It is just better to make one network request than many.
On top of that if you took advantage of the application router properly it may also query the database, especially since it is responsible for assigning subscriber identity and function selection.
To summarize what we got so far for a single call in this 3-app service:
- 4 times SipSession with attributes and properties
- 3 times SipApplicationSession with attributes and properties
- 2 times SIPDialog
- Whatever transactions are in progress multiplied by at least 3 (client and server)
- 3 times the timers
- 3 times JDBC over the network, once for each app, each in separate DB transaction
- 3 times call the getNextApplication() to the application router, each potentially querying the database again
- ..and I am probably forgetting something
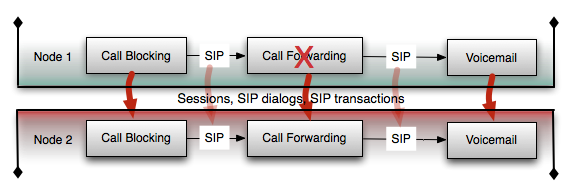
Fault tolerance
When you account for the fault-tolerance, you need to have at least one replica of the above state. Replication occurs all the time continuously and has very serious additional consequences for memory, network traffic and CPU utilization. Application Routing also amplifies any gaps in time where a failure is unrecoverable depending on the replication policy.
In the end, with or without fault tolerance, having this service implemented in 3 applications probably costs around 3 times more in terms of consumed hardware, development/testing and has much slower response time compared to a monolithic application that does the same with simple if .. then .. else statements. Application chaining doesn't look like such a good idea any more.
Converged HTTP applications spaghetti
Unlike SIP, HTTP servlet applications do not allow composition. Usually each SIP application would have some sort of Web UI in the same WAR module allowing users and administrators to configure the system or user profiles. Do you really want your service to have 3 different entry-points of configuration? Block users from one app, configure forwarding in another and set the voicemail greeting in a third app. One option would be to use a Java Portal (JSR-168 or JSR-286 with WSRP) portlets to combine the UI. That may or may not work. I am not going to cover the limitations of Java Portals, but the fact is that it has some limitations, greater complexity, performance penalty and so on. If you turn on and off application from the application router, your application router will have to update the portal configuration to reconfigure the UI.
In most cases you will have a separate Web UI application that is aware of the schema used by all 3 applications, which limits the potential of the SIP applications to grow independently from each other. A modification in one app may force a change in your Web UI app.
No matter which way you go, there will be a chain of dependencies that your applications or the application router should be aware of, which breaks the promise of isolation to some extent.
Application Composition is not a design pattern
You shouldn't design or plan your service to be in different applications. Sip Servlets application composition is not a chain of responsibility implementation. Applications are deployment units, not architectural building blocks. You don't design your Web Services specifically to be orchestrated with BPEL and certainly not with a particular BPEL implementation. Just like application routing, BPEL's power is in the integration.
Application composition is probably best fit for unrelated services from different vendors that consume different databases and in most cases run without being chained together with other applications. Application routing is OK as long as the actual application chaining is rare and applications are self-sufficient as individual services that have a single Web access point.
In that sense, application routing can also be used as a cheap rolling upgrade technique - just switch the requests to a new application and the new sessions will arrive in your new app while the old sessions will continue to go to the old app until they finish. AFAIK this will work on any container.
In conclusion, if you are an architect or developer you should forget that application routing exists. It is sysadmin job to reconfigure applications if they see fit or have no other choice.











{kind=link}